Notes on Teaching GPT-3 Adding Numbers
by Ekin Akyürek and Afra Feyza Akyürek
June 6, 2022 (edited on June 14, 2022)

Large language models (LLMs) effectively tackle a surprisingly wide set of tasks ranging from machine translation to making logical inferences to understanding jokes (Chowdhery et al., 2022) right out of the box. While researchers have long observed that complex, multi-step reasoning is more challenging for these models, a number of recent papers have shown that we can improve the reasoning abilities of LLMs by guiding them to write step-by-step explanations —analogous to using scratch paper when solving a math problem— before giving the final answer (Wei et al., 2022; Nye et al., 2021; Cobbe et al., 2021). Notably, the recent work (Zhou et al., 2022; Wang et al., 2022; Wei et al., 2022, Nye et al., 2021) combines the ideas from the prompting research (Brown et al., 2020) and the work on explanations (Ling et al., 2017) by enabling LLMs to show their explanations without supervised training. In some tasks, e.g., solving grade-school math problems, this enhanced prompting technique, named scracthpad or chain-of-thought prompting, can drastically improve over standard prompting. But designing these scratchpad prompts feels more like art than science — a handful of task-specific examples have been shown to work but a systematic understanding of what is essential is yet to be discovered. What makes a good scratchpad? How robust are they in terms of content and syntax? In this post, we will break down a useful scratchpad for a simple numerical addition task to answer these questions. The code for the experiments is released here.
Background: “Communicating” tasks to language models
(suggested reading for the background: Liu et al., 2021)
How can we turn an LLMs—a neural net trained to predict the next word given the previous text—into a model that performs a specific task? The simplest approach is prompting: you just provide the question in natural language, such as "Q: What is 134 plus 266? A: " and achieve high zero-shot ability across many tasks. However, this kind of zero-shot prompting can fail in novel tasks such as adding together larger numbers than shown — we can speculate that either the form in which the question is presented is lacking in putting the model into the “right” state of mind or the specification is degenerate to precisely describe the task (addition vs string concatenation). To address the latter concern, an even better approach is prompting the model with a few example input-output pairs:
xxxxxxxxxxQ: What is 235 plus 266?A: 601.Q: What is 87 plus 55?A: 142.Q: What is 134 plus 266?A: ___
With such few-shot prompting, one hopes to specify the target task better with these example input-output pairs. In fact, recent papers (Brown et al., 2020) show in various NLP tasks that few-shot prompting is superior to zero-shot prompting. This exciting new phenomenon—the ability to infer (or learn) the task from input examples—was coined as in-context learning; albeit, experiments in this post will demonstrate that simple in-context learning does fail in fairly novel/unknown tasks.
(See Olsson et al., 2022; Xie et al., 2022 and Chan et al., 2022 for why and when in-context learning might work)
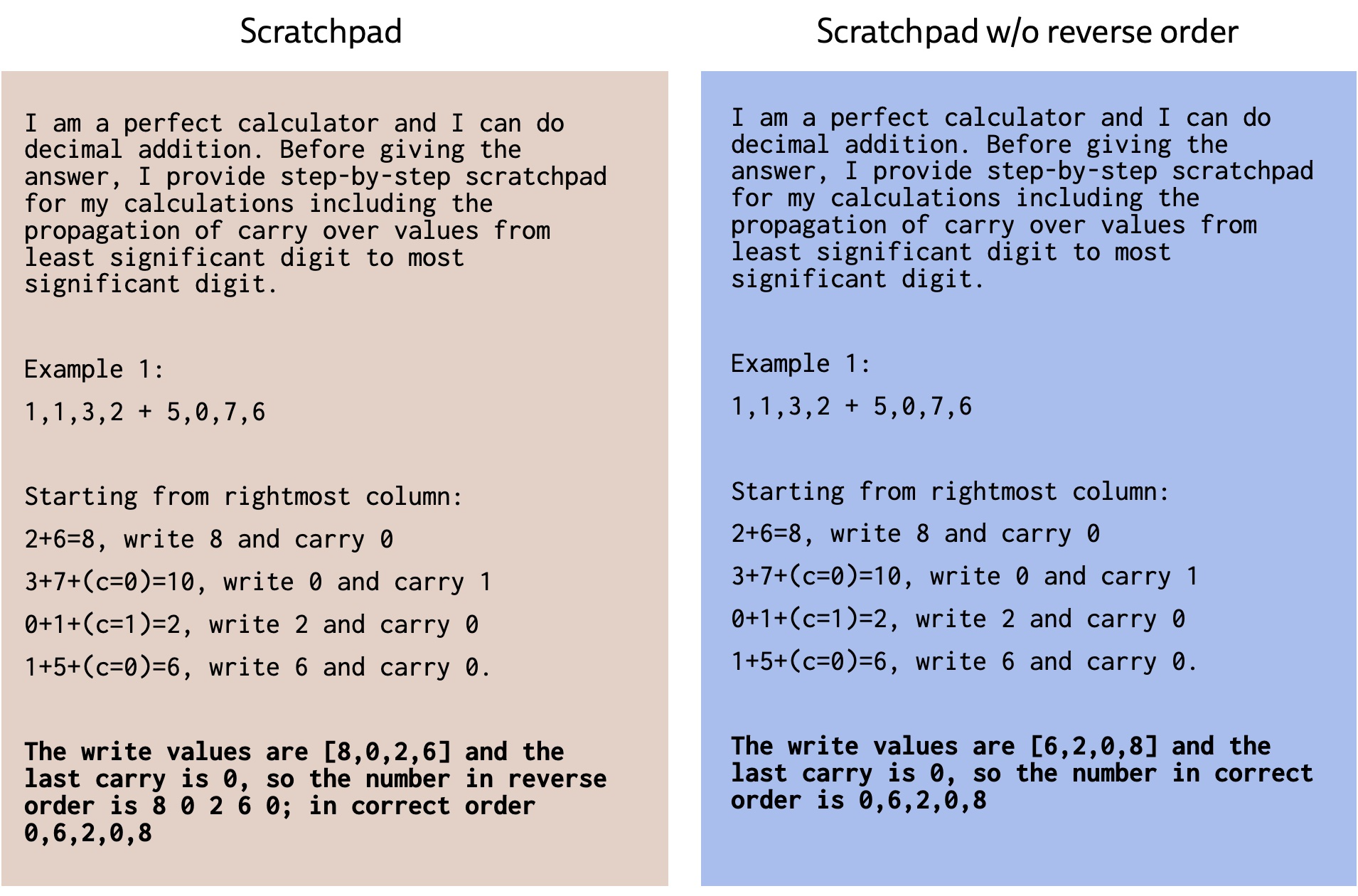
The shortcomings of few-shot prompting did not stop the enthusiasts of large language models. A critical step toward bootstrapping the in-context learning ability of LLMs proposed was including a detailed chain-of-thoughts (we will refer to it as scratchpad since we experiment with addition) to the few-shot examples provided in the input (Zhou et al., 2022; Wang et al., 2022; Wei et al., 2022, Nye et al., 2021). In Figure 1, we present an example of a scratchpad that contains step-by-step explanations leading to the solution. Scratchpad style prompting encourages the model to divide the problems into intermediate steps that hopefully render reaching the correct answer easier.
In an attempt to better understand scratchpads, we dissect the components that go into the scratchpad template on the task of adding two integer numbers. Why addition? It’s simple, it is likely familiar to LMs, and we can write down exact algorithms for solving it. Despite all this, addition is often claimed to be hard for LMs (though we’ll test that claim more precisely in a moment.)
Analysis
When do scratchpads help?
Without a further ado, let's start prompting GPT-3 (codex-GPT-3 code_davinci_0021) for the simple integer addition problem as in Nye et al., 2021. We follow the template provided in the original GPT-3 paper: GPT-3 style zero-shot and few-shot prompts in Figure 1. We will refer to these GPT-3 style prompts few-shot and zero-shot prompts for brevity. For the experiments, we used three examples with the same summands in all prompts. We tested the model with 100 number pairs for each digit and will use the same numbers in all of the experiments in this post. Here is our scratchpad prompt:

We will look at the details of this scratchpad prompt later in this post, but let's first analyze the top-level results presented
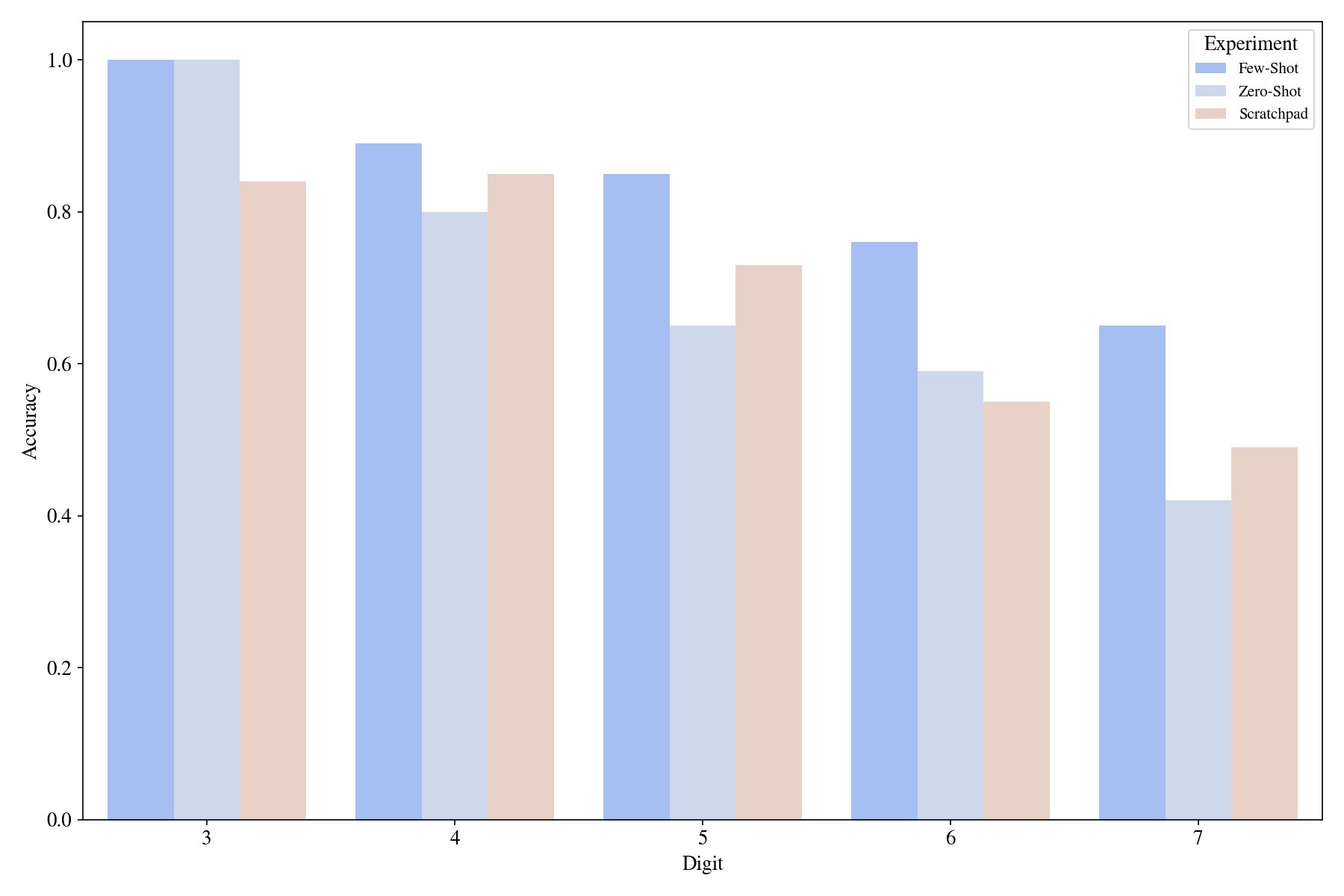
The first impression is that GPT-3 doesn’t benefit from the reasoning steps we provided in the scratchpad (3, 5, 6, and 72 digit results)! One can argue that either this scratchpad is not optimized enough, or maybe GPT-3 memorized this format (Q: _ A: _ no delimiter between digits, etc.) and overfits to it. A particular nuance to note is that the tokenizer of GPT-3 does not split numbers by each digit (you can test it here). So, if there is, the algorithm that GPT-3 learned for addition probably is not digit-by-digit, yet we provide it with a digit-by-digit algorithm.
But does GPT-3 understand addition in a general way or just this specific prompt? Let’s evaluate this by inserting delimiters between numbers in the original few-shot prompt:

Now the model fails to learn this equivalent arithmetic task, with a delimiter, by using the few-shot prompting!3
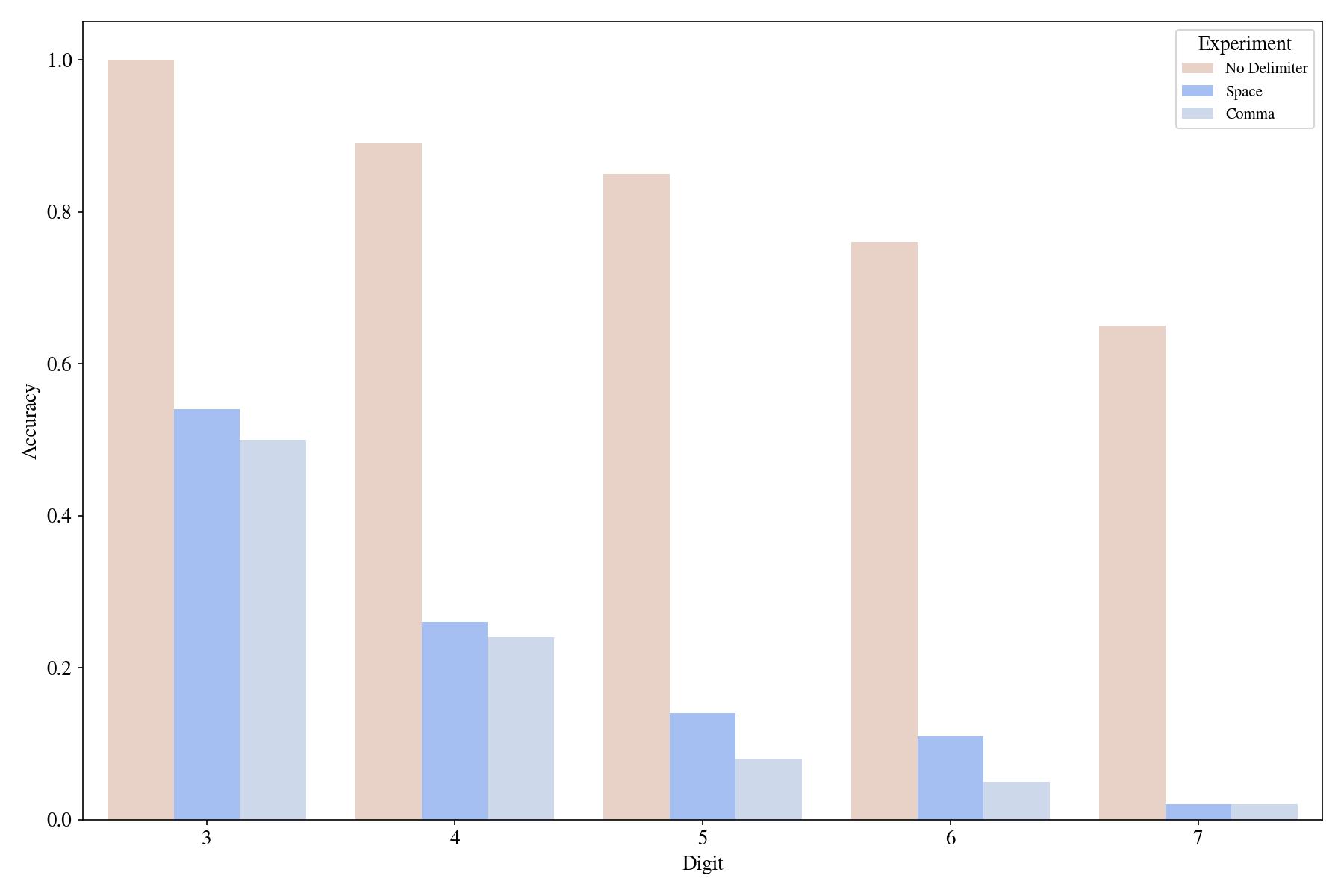
So, it can't learn this task in-context with few-shot prompting when a slight variation is introduced. Will our scratchpad help in this "novel" arithmetic task?
We will continue with the comma-delimited version of the task as we found it better than the space version with this particular scratchpad. Also, the format is a bit different in the scratchpad (for example "+" vs plus), but my qualitative finding is that using "+" makes the few-shot prompt performance worse.

Let's see how scratchpads compare to the few-shot prompting in the comma-arithmetic task:
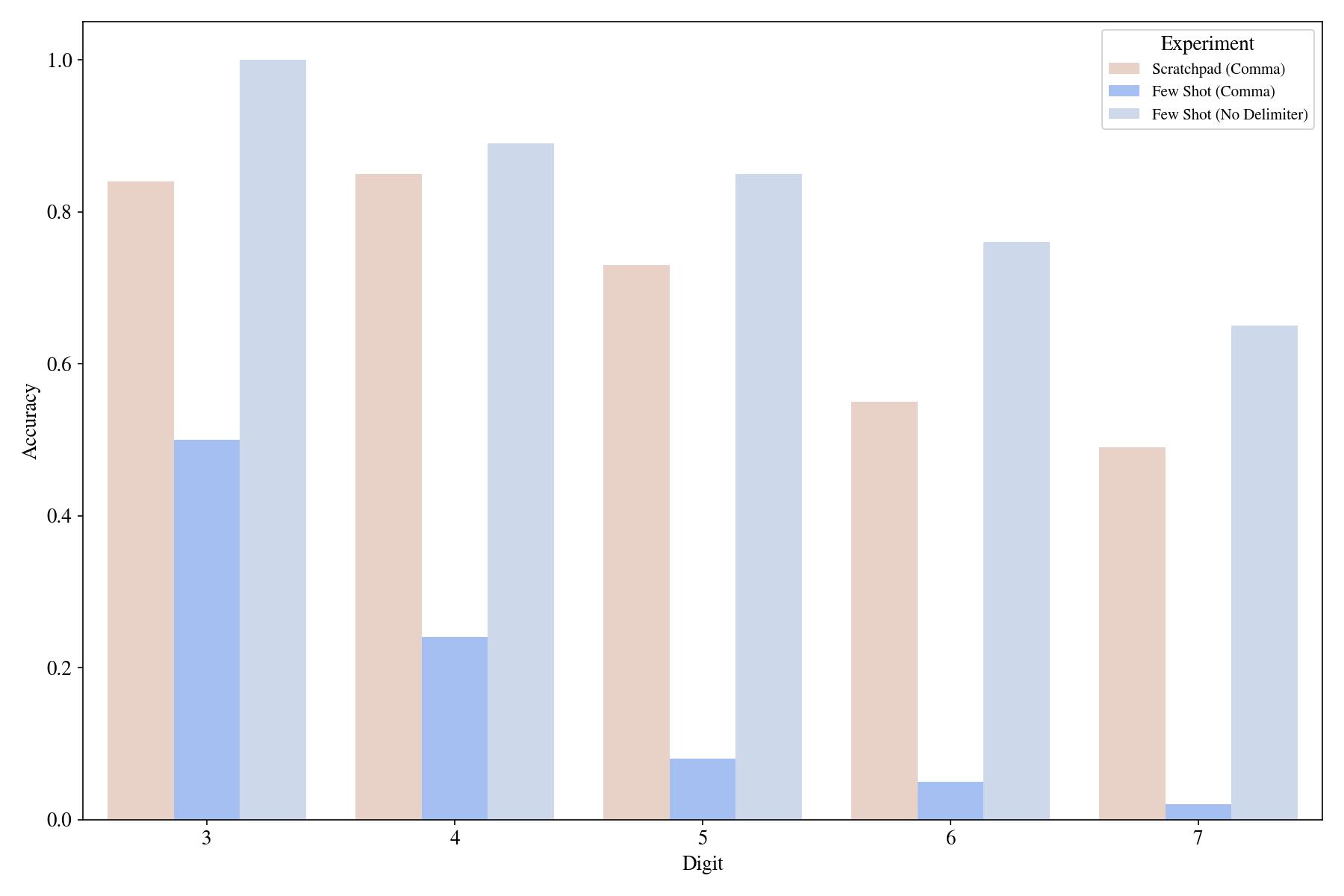
Scratchpads improve significantly in “novel” arithmetic variations where few-shot prompting completely fails! There is still one caveat that it is lower than the original few-shot non-delimited prompting. But we only use three examples in the prompt for this comparison, maybe scratchpads scale better with more examples than the few-shot prompting?
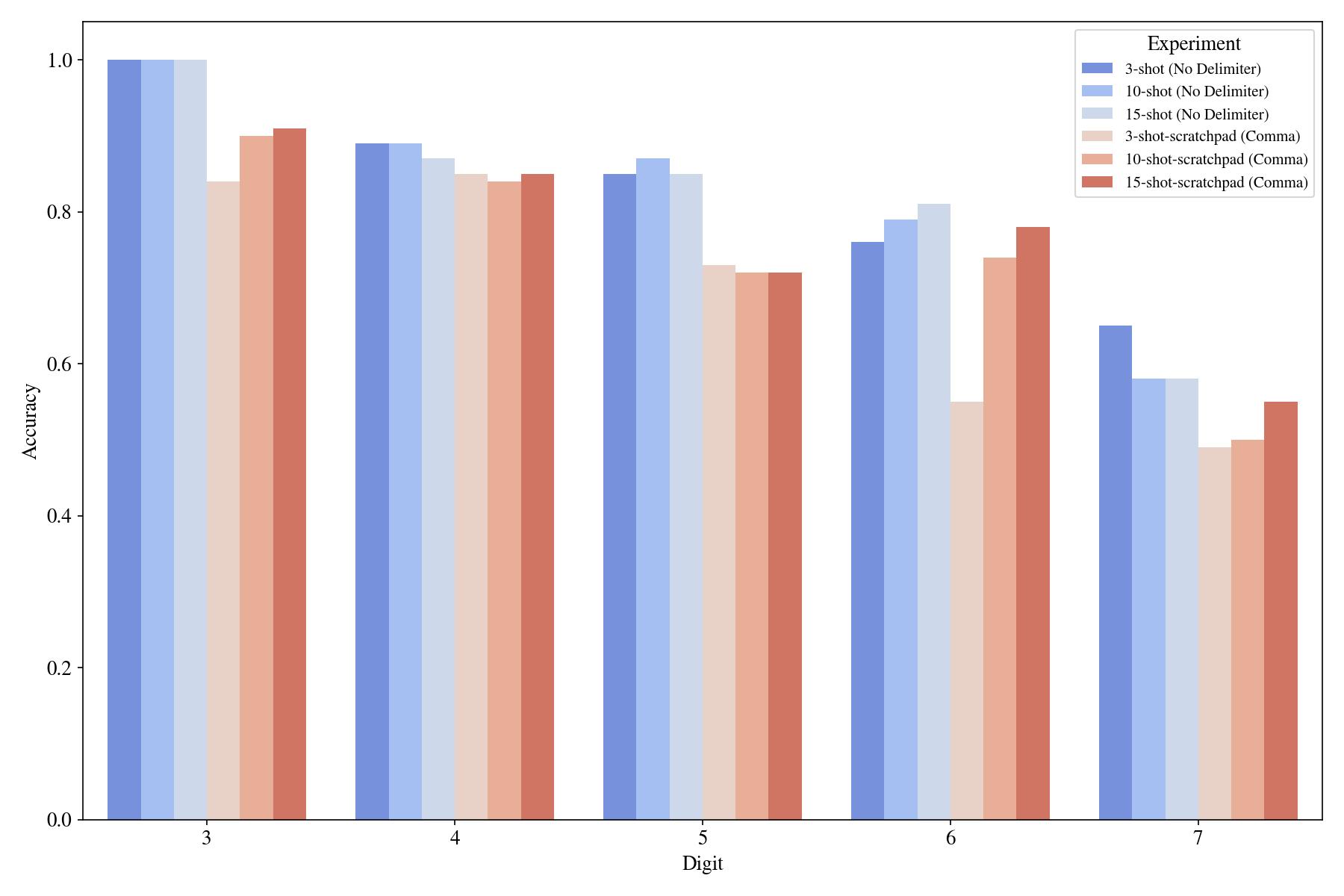
Scratchpads scale better than few-shot prompting with the growing number of examples in the input!4 Although we couldn't surpass GPT-3 (when it's using a familiar format) by using scratchpads, we can still analyze the effects of different parts of the scratchpad in the novel format.
What should a scratchpad include?
Intermediate Values
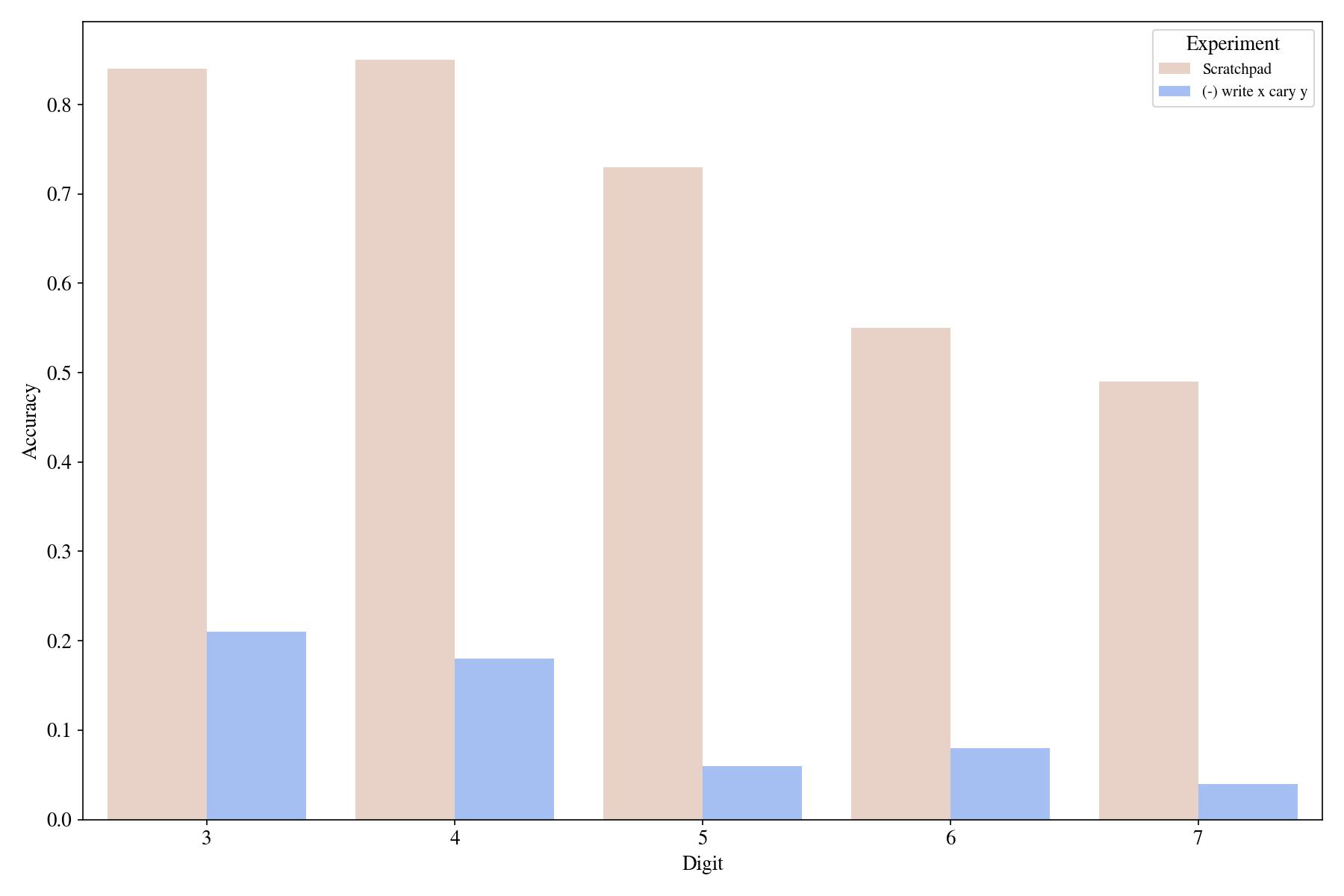
The most crucial thing that a scratchpad enables is explicit intermediate value storage. For example, in Figure 4 we spell out "write" and "and carry" in each step. Given these intermediate values, the task that the model needs to do becomes trivial which is simply to gather the intermediate write values at each step. We conduct ablations where we skip indicating write and carry-over values and remove the reverse ordering.

It seems that explicitly indicating write and carry-over values are very effective in getting the model to achieve the task:
Another intermediate value in the original scratchpad was the reverse of the output number. We consider two different scratchpads in one of which we omit the intermediate reversed number.
Similarly, collecting numbers in the reversed order first and then reordering them helps the model to succeed (Plot 5). Note that both prompts are evaluated for the final correctly-ordered answer.
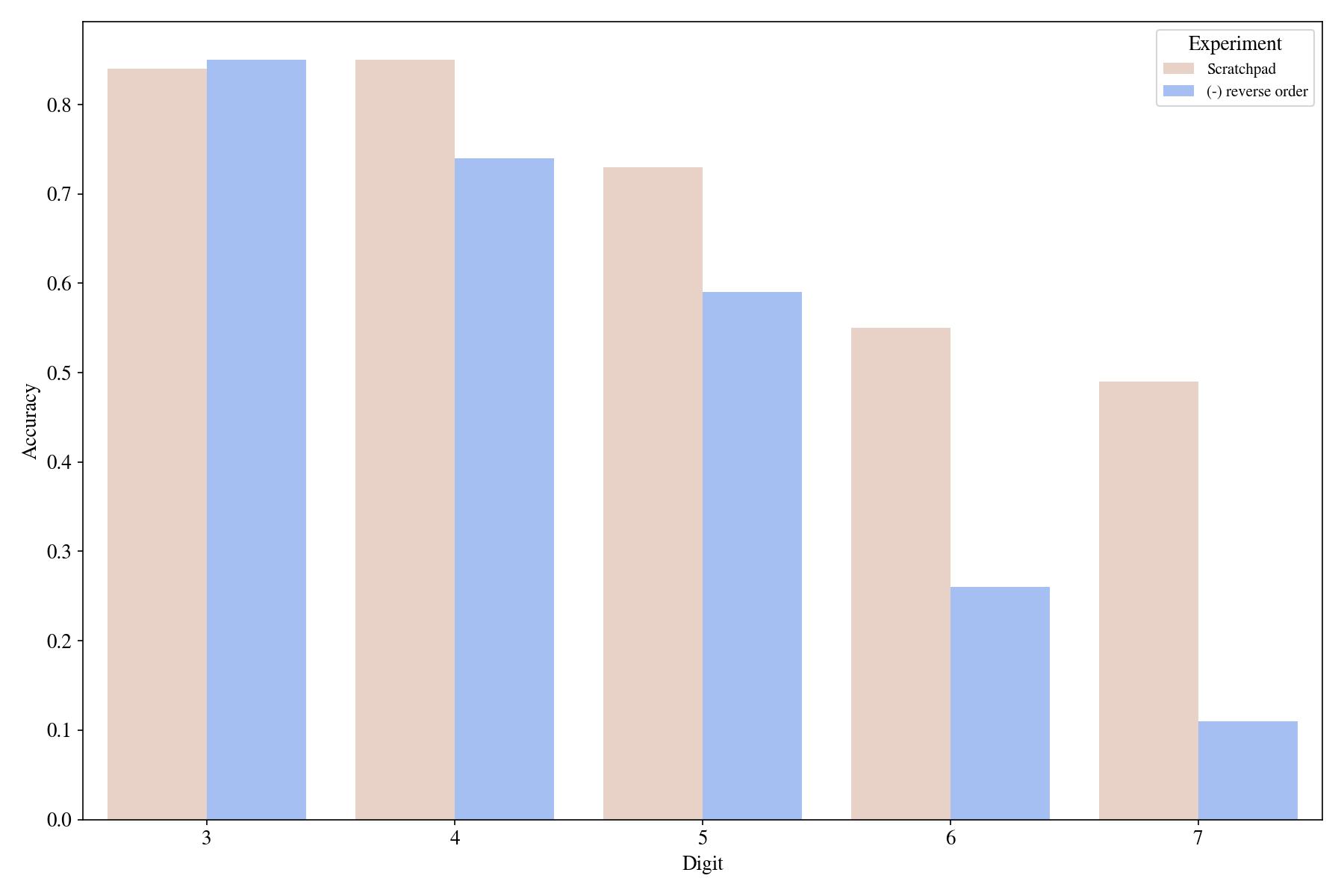
In conclusion, scratchpads help divide a problem into relatively easy subproblems. Given the results of each subproblem, achieving the final goal becomes extremely easy. A good scratchpad requires explicitly printing all of the intermediate results produced in the intermediate problems!
What should their style look like?
Breadcrumbs
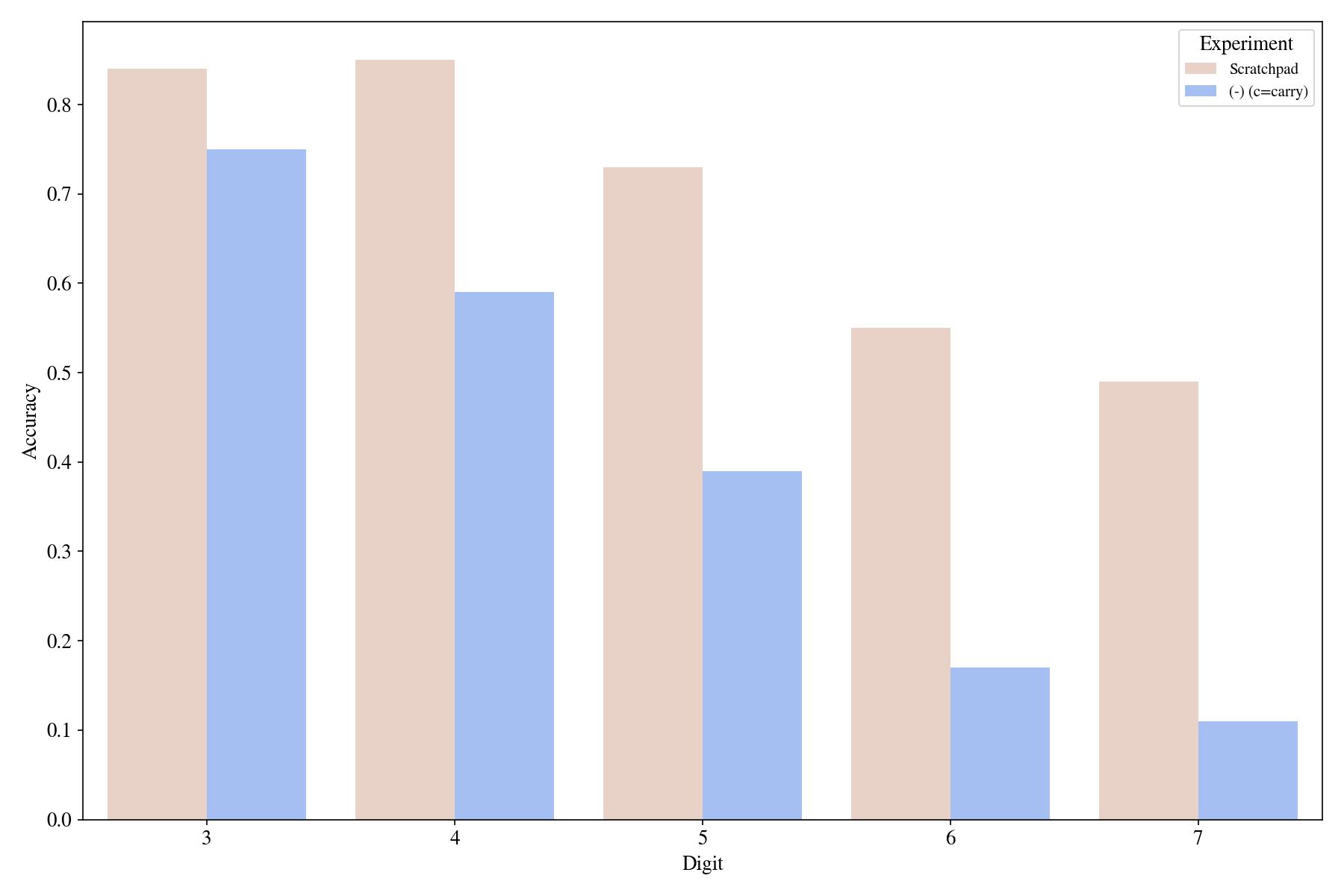
As mentioned in this tweet, explicitly writing the intermediate values' position or type information helps the model align the values. In the below Figure, we have marked the carry-over values in tri-way sums, as noted with (c=value) marks in Figure 6.

Now, we test the effect of removing these carry-over markings from the prompt and find out that they are also consistently helpful across different number of digits, including the out-of-distribution 7-digit summation.
Magical Incantations
People found that starting the prompt with "I am smart ...." increases the accuracy of zero-shot prompting, so we have a similar thing in our main prompt, "I am a perfect calculator." We looked at the effect of such statements being in the prompt and found out slight to no difference compared to starting with "I am a robot".

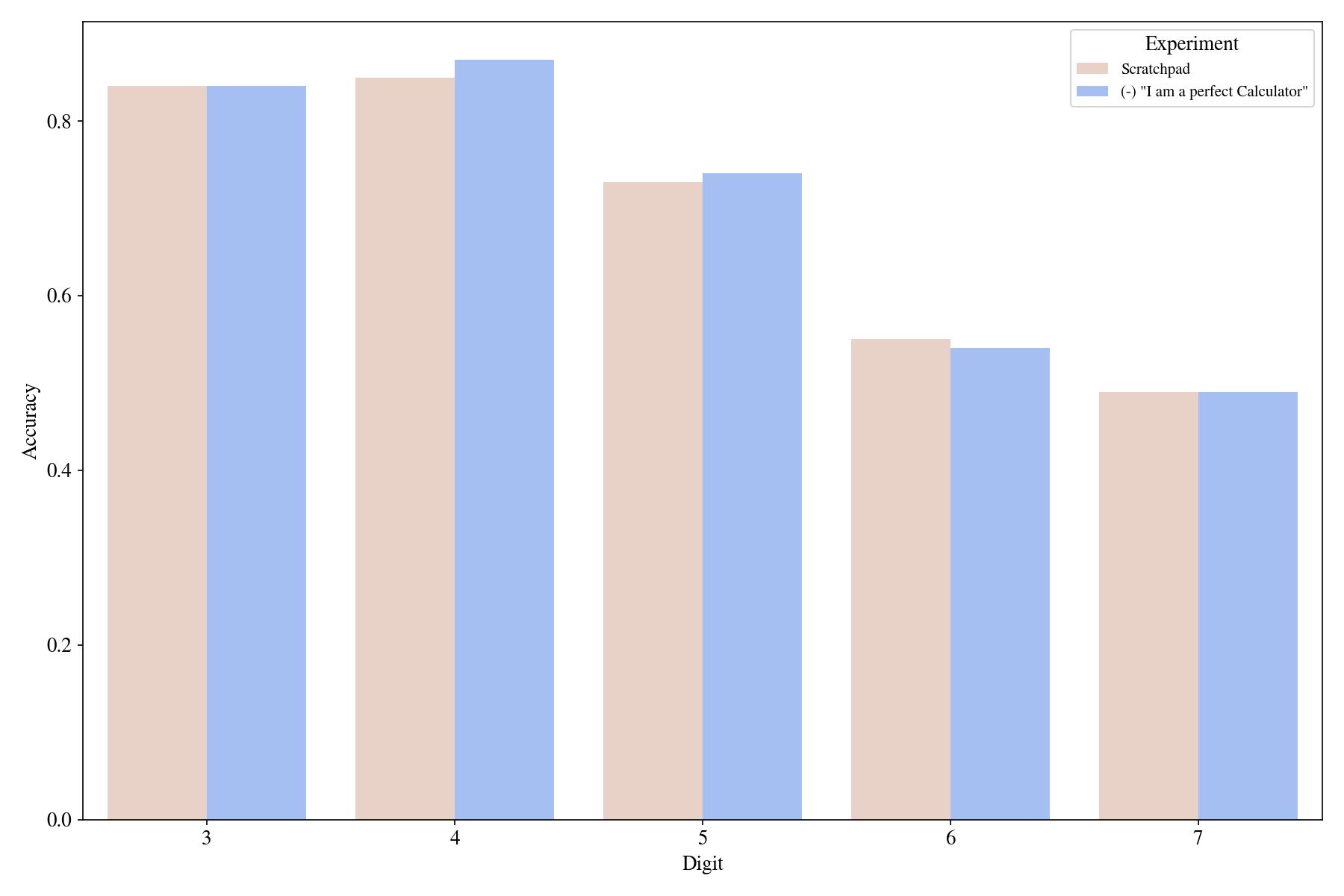
Explicit Instructions for Step-by-Step Reasoning
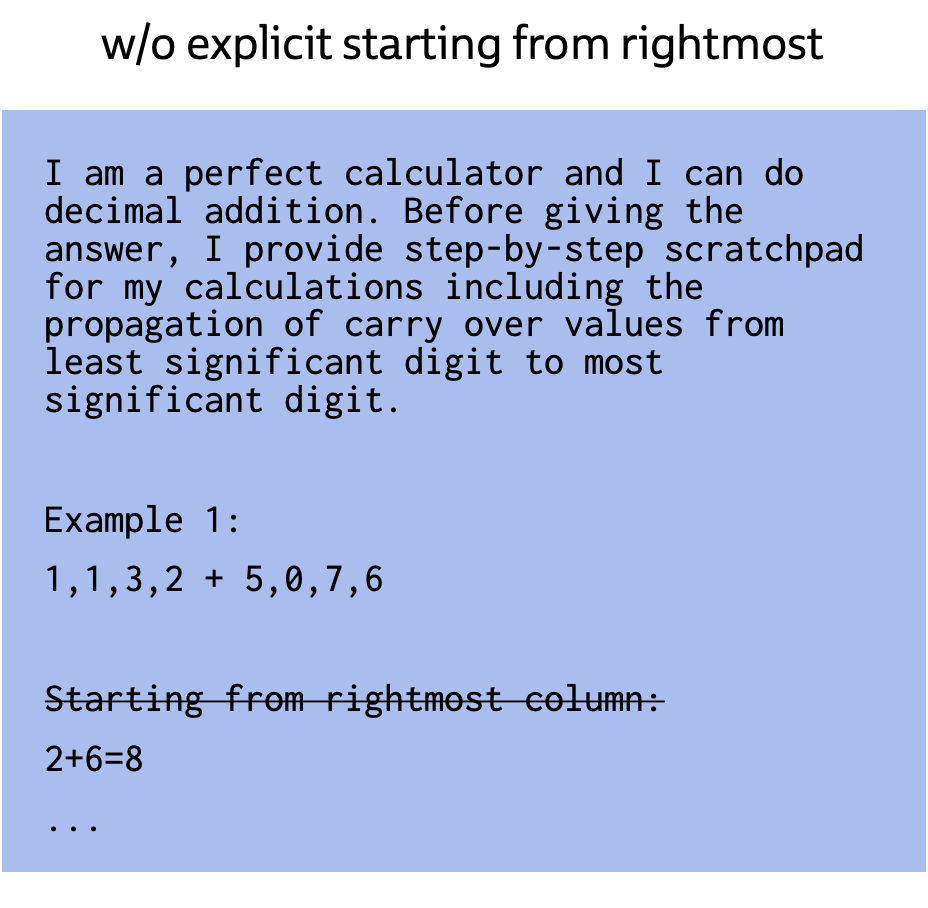
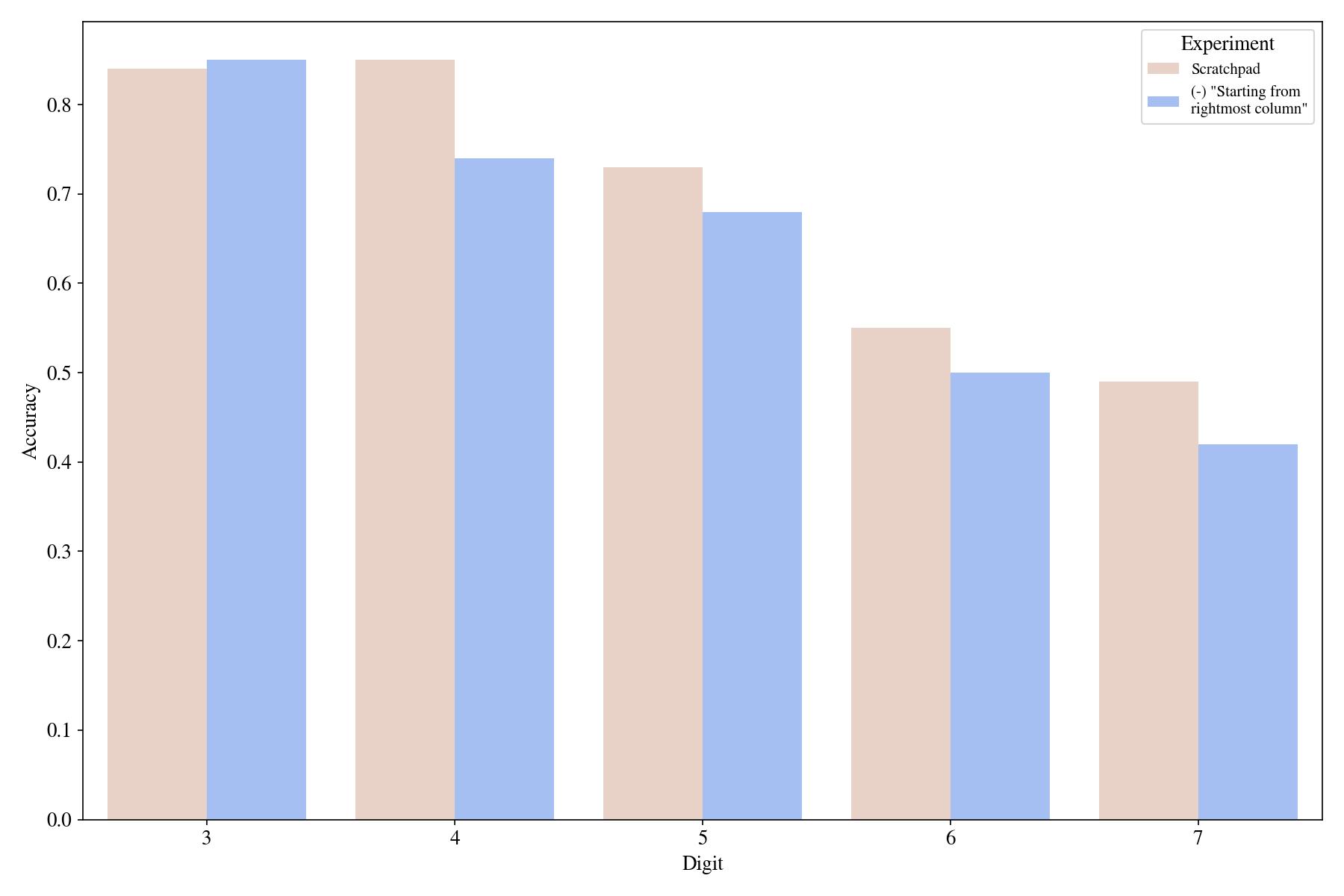
Before starting the scratchpad, we explicitly said: "Starting from the rightmost column" to hint the model that the algorithm starts from the least significant digit. We now remove that statement to see if it has any effect on it.
We found a non-negligible effect:
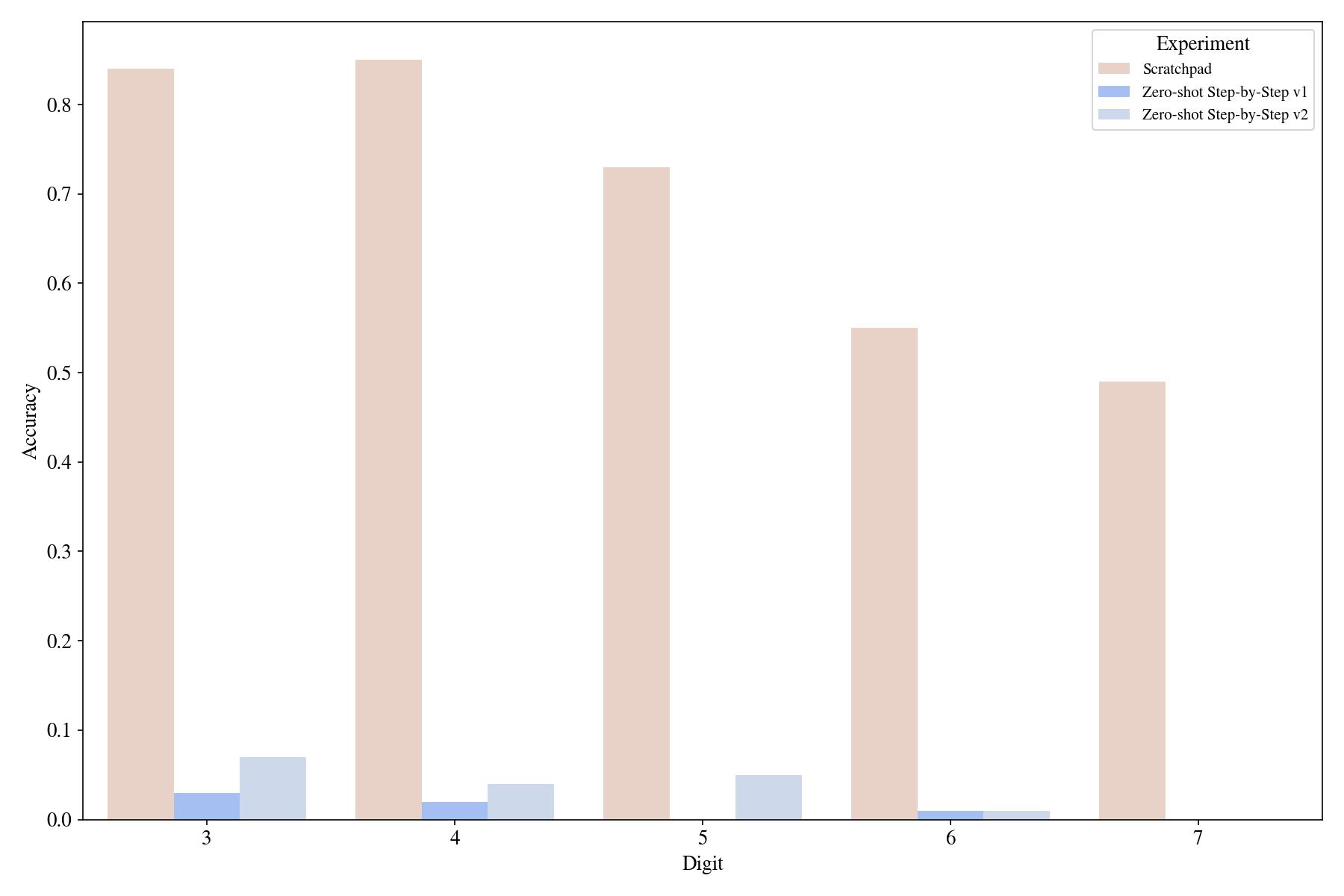
Can we do this zero-shot?: Some suggest that you can trigger this kind of reasoning in a zero-shot manner by just appending "Let's think step-by-step":
We tried two such zero-shot prompts,

and none worked for the arithmetic task.
In conclusion when it comes to style, a scratchpad must not leave anything to interpretation by the model and place appropriate markers. For instance, the tri-way sum without carry-over markers (1+8+9) requires the model to infer which summand is the carry-over, and thus results in poor performance.
Conclusion
In this post, we tried to categorize components of scratchpads and analyze their effects based on a prototype addition task. We found that scratchpads help LMs to tackle novel tasks by breaking them into known subtasks that can be solved in latent scratchpad steps. That said, the current status of scratchpad/chain-of-thought prompting is more like alchemy: we do not know how it actually works and why it is useful. If we want to learn better ways of "coding" these language models into problem solvers, we need more empirical (e.g., Olsson et al., 2022) and theoretical (e.g., Xie et al., 2022) analysis on this topic.
Acknowledgments
We thank Jacob Andreas for his valuable feedback on the experiment design and on the writing, and we thank Denny Zhou for providing his comments on the initial draft.
Footnotes and Citation
Citing this blog post:
@misc{akyurek2022gpt3addition,author = {Akyurek, Ekin and Akyurek, Afra Feyza},title = {Notes on Teaching GPT-3 Adding Numbers},url = {https://lingo.csail.mit.edu//blog/arithmetic_gpt3},year = {2022}}
text-davinci-002 and spent some money, but then we realized Codex is free and all the relative ordering of success of different prompts stayed the same. In addition, the Codex is overall better than the text-based model. ↩